

3 min
AI Insights39m ago
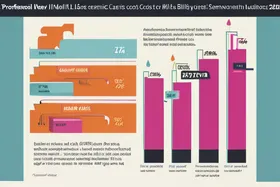
Reduza os Custos de LLM: Cache Semântico Diminui Contas em 73%
O cache semântico, que se concentra no significado das consultas em vez da redação exata, pode reduzir drasticamente os custos da API LLM, identificando e reutilizando respostas a perguntas semanticamente semelhantes. Ao implementar o cache semântico, uma empresa alcançou uma redução de 73% nos custos da API LLM, destacando a ineficiência do cache de correspondência exata tradicional no tratamento das nuances das consultas do usuário e o potencial de economias de custos significativas por meio de estratégias de cache mais inteligentes.

20











Discussion
Join the conversation
Be the first to comment